本篇對[改善資料品質]階段性的Coding實例,方便學習的朋友能一次看到目前的進度以coding演示。
首先匯入需要的模組
from functools import partial
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
讀取資料 含訓練集和測試集
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
#測試集
test_set = pd.read_csv('data/test.csv', dtype=column_types)
觀察缺值
#觀察訓練集的缺值
print(train_set.isnull().sum())
#觀察測試集的缺值
print(test_set.isnull().sum())
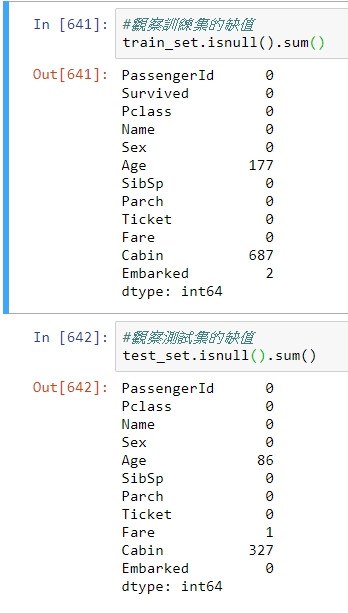
訓練集與測試集的Age以及Cabin皆有缺值,Age缺值較少採捕值處理,Cabin則缺值過多採丟棄該欄位處理。code有使用python的function tool函式partial,(partial的目的是在將一函式的特定參數固定,以便每次呼叫該函式時不用再定義該參數),請參照官方網站的文件說明。
#對dataframe丟棄指定欄位
def drop_col(df, col):
return df.drop([col], axis=1)
#將丟棄欄位參數定為缺值過多的Cabin
drop_cabin_col = partial(drop_col,
col='Cabin')
#對dataframe特定欄位以總體算術平均數做補值
def fillna_with_mean(df, col):
df[col] = df[col].fillna(df[col].mean())
return df
#特定欄位參數設為Age
age_fillna_with_mean = partial(fillna_with_mean,
col='Age')
#特定欄位參數設為fare
fare_fillna_with_mean = partial(fillna_with_mean,
col='Fare')
#對dataframe特定欄位以最常出現的值做為補值
def fillna_with_most_freq_val(df, col):
most_freq_val = df[col].value_counts().index[0]
df[col] = df[col].fillna(most_freq_val)
return df
#欄位定為Embarked
embarked_fillna_with_most_freq_val = partial(fillna_with_most_freq_val,
col='Embarked')
def apply(Funclist, df):
if len(Funclist) > 0:
return apply(Funclist[1:], Funclist[0](df))
else:
return df
#train set的資料處理流程
train_processing_steps = [drop_cabin_col,
age_fillna_with_mean,
embarked_fillna_with_most_freq_val]
#train set的資料處理流程
test_processing_steps = [drop_cabin_col,
fare_fillna_with_mean,
age_fillna_with_mean]
預處理訓練集和測試集
train_set = apply(train_processing_steps, train_set)
test_set = apply(test_processing_steps, test_set)
#訓練 + 測試集(先結合在一起方便做特徵工程)
concat = pd.concat([train_set, test_set])
觀察處理完畢的資料集缺值狀況,已經完全無缺值(除了Survived欄位以外,原因是測試集本來就沒有Survived欄位)。
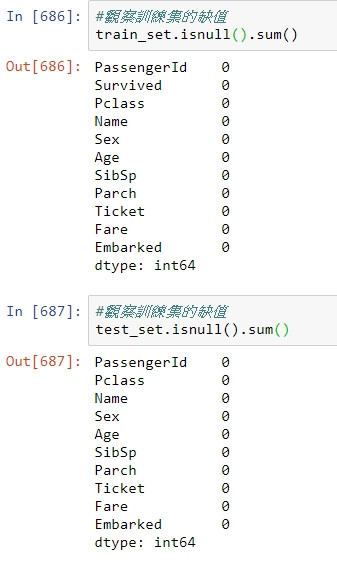
快速以一篇短文演示到目前為止的進度,但補值還有許多有趣的方式,下一篇的目標將放在演示一個有趣的想法;"以個人的稱謂來推斷年齡",進一步以此方法做補值。

